PAF
…Une brique dans la mare de la HA
Qui suis-je ?
- Jehan-Guillaume de Rorthais
- aka. ioguix
- utilise PostgreSQL depuis 2007
- dans la communauté depuis 2008
- @dalibo depuis 2009
- intro sur la HA
- intro sur Pacemaker
- pourquoi PAF
- Fonctionnalités de PAF
Haute Disponibilité

## Rappels sur la HA
- High Availability, aka. Haute disponibilité
- Intégrée dans un Plan de Continuité de Service
- En gros, on double tout
- Bascule automatique ou non ?
## Bascule auto: techniquement
Complexe à mettre en œuvre:
- comment détecter une vraie défaillance ?
- le maître ne répond plus ?
- est-il vraiment éteint ?
- est-il vraiment inactif ?
- comment réagir à une panne réseau ?
- comment éviter les split brain ?
## Bascule auto: apprentissage
La route est (presque) droite mais la pente forte:
- plusieurs problèmes/mécaniques à comprendre: quorum, fencing, watchdog, …
- configuration pointue
- maintenances complexes
- documenter, documenter, documenter
- tester, tester, tester
Si vous ne voulez pas de complexité, n’en faites pas.
# Pacemaker
Apprentissage difficile…
…Toute résistance est futile.
Généralités sur Pacemaker
- est LA référence de la HA sous Linux
- est un “Cluster Resource Manager”
- supporte les fencing, quorum et watchdog
- multi-service, avec dépendances, ordre, contraintes, règles, etc
- s’interface avec n’importe quel service
- chaque service a son Resource Agent
- RA stateless ou multi-state
- API possibles: script OCF, upstart, systemd, LSB
## Archi Pacemaker
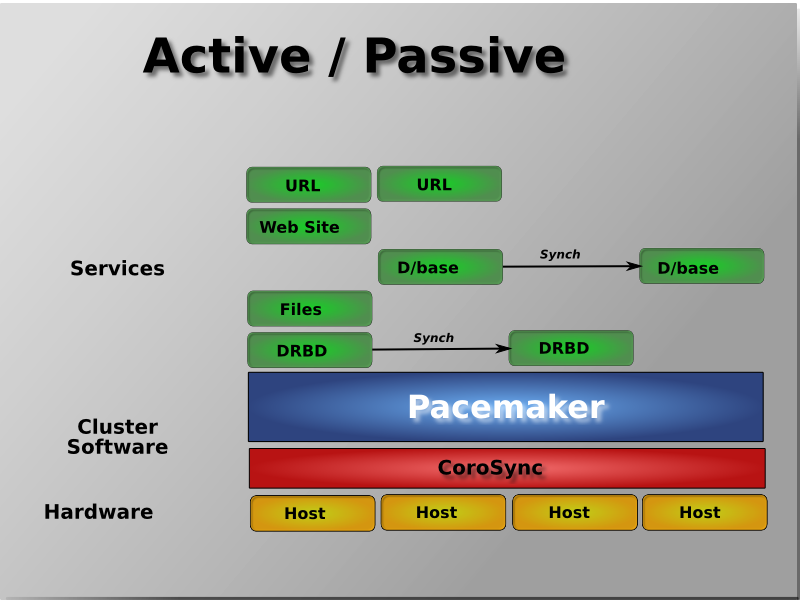
## Mécanique du CRM
- sorte d’automate
- 4 états: arrêté, démarré, slave ou master
- calcul de transitions pour passer d’un état à l’autre
- API classique (eg. systemd): start, stop, monitor(status)
- API OCF: start, stop, promote, demote, monitor, notify
- cas d’une ressource multi-state:

Action notify
- seulement possible avec RA OCF
- déclenchés avant et après chaque action
- permet au RA d’effectuer des opérations

Infos du notify
Variables transmises au RA lors d’un ‘pre-promote’:
active => [ ],
inactive => [
{ rsc => 'pgsqld:2', uname => 'srv1' },
{ rsc => 'pgsqld:0', uname => 'srv2' },
{ rsc => 'pgsqld:1', uname => 'srv3' }
],
master => [ ],
slave => [ ],
promote => [ { rsc => 'pgsqld:0', uname => 'srv1' }],
demote => [ ],
start => [
{ rsc => 'pgsqld:0', uname => 'srv1' },
{ rsc => 'pgsqld:1', uname => 'srv3' },
{ rsc => 'pgsqld:2', uname => 'srv2' }
],
stop => [ ],
type => 'pre',
operation => 'promote'
l’exemple ici ressemble au démarrage du cluster.
Master score
- pondère quel slave promouvoir en master
- un slave doit avoir un score positif pour être promu
- pas de promotion si aucun score
- positionné à la discrétion du RA et/ou de l’administrateur
## Histoire
- conférence sur Pacemaker/pgsql en 2012
- traumatisme…
- …et une personne vient causer repmgr
- il fallait faire quelque chose…PAF débuté en 2015
- entre temps d’autres projets autour de Pacemaker
- auteurs: Maël Rimbault, moi même
## Objectifs
- garder Pacemaker: il fait tout et bien à notre place
- se concentrer sur notre métier: PostgreSQL
- coller à l’API OCF, à Pacemaker et les respecter
- garder une configuration du RA SIMPLE
- ne supporter QUE le multi-state
- ne supporter QUE la Streaming Replication
- avoir un code compréhensible et documenté
## Versions
Deux versions pour les attraper tous!
- 1.1: jusqu’à EL6 et Debian 7
- …ou jusqu’à Pacemaker 1.12/corosync 1.x
- 2.0: depuis EL7 et Debian 8
- … ou depuis Pacemaker 1.13/Corosync 2.x

## Configuration
- system_user
- bindir
- datadir (oops)
- pgdata
- pghost
- pgport
- recovery_template
- start_opts
Configuration
Agent pgsql historique dans Pacemaker:
- pgctl
- start_opt
- ctl_opt
- psql
- pgdata
- pgdba
- pghost
- pgport
- pglibs
- monitor_user
Configuration
Encore ?
- monitor_password
- monitor_sql
- config
- pgdb
- logfile
- socketdir
- stop_escalate
- rep_mode
- node_list
- restore_command
Configuration
C’est pas fini…
- archive_cleanup_command
- recovery_end_command
- master_ip
- repuser
- primary_conninfo_opt
- restart_on_promote
- replication_slot_name
- tmpdir
- xlog_check_count
- crm_attr_timeout
## Configuration
Et les derniers pour la route:
- stop_escalate_in_slave
- check_wal_receiver

Son savoir faire
…on ouvre le ch^Wcapot.
Entrailles
- écrit en perl
- demote = stop + start (= slave)
- mécanique d’élection en cas de failover
- détecte les types de transitions grâce aux notify (recovers et move)
## Recover d’un standby
Transition: stop -> start

Démo recover d’un slave:
## Recover d’un master
Transition: demote -> stop -> start -> promote

Démo recover master:
Failover et élection

Démo failover avec élection:
## Vous pensiez en avoir fini ?

Échange de rôle
- uniquement en 2.0
- le standby désigné valide les données reçues du master
- le standby annule la promotion si intérgation de l’ancien master non garanti
Démo échange des rôles:
# Où
«Mais où est donc passé ce chien ?»
Des questions ?

