Bonnes pratiques en PostgreSQL
Ou comment maintenir ses instances en conditions opérationnelles
Dalibo & Contributeurs
PostgreSQL

L’intérieur de PostgreSQL
Au programme : quelques bonnes pratiques
- La supervision
- L’audit
- La mise à jour applicative
- Le contrôle de la fragmentation
- La sauvegarde
- L’optimisation SQL
Mon entreprise : Dalibo
- Le spécialiste français de PostgreSQL crée en 2005
- Coopérative proposant des services :
- de conseil
- de support
- de formation
- métier principal : DBA polyvalent
- Site : http://dalibo.com
Qui suis-je ?
- Thibaut MADELAINE
- DBA PostgreSQL à Dalibo depuis 4 ans
- Mainteneur de
pitreryetsqlserver2pgsql
Au programme : quelques bonnes pratiques
- La supervision
- L’audit
- La mise à jour applicative
- Le contrôle de la fragmentation
- La sauvegarde
- L’optimisation SQL
La supervision
| sy.pɛʁ.vi.ze |
« Se placer au-dessus pour voir, remarquer, prendre des mesures »
Objectifs de la supervision
- Améliorer / mesurer les performances
- Améliorer l’applicatif
- Anticiper / prévenir les incidents
- Réagir vite en cas de crash
Acteurs concernés
- Administrateur de bases de données
- surveillance, performance
- mise à jour
- Administrateur système
- surveillance, qualité de service
- Développeur
- correction et optimisation de requêtes
Indicateurs côté système d’exploitation
- Charge CPU
- Entrées/sorties disque
- Espace disque
- Sur-activité et inactivité du serveur
- Temps de réponse
Indicateurs côté base de données
- Nombre de connexions
- Volumétries
- Requêtes lentes et/ou fréquentes
- Nombre de transactions par seconde
- Ratio d’utilisation du cache
- Retard de réplication
check_pgactivity
- Script de monitoring PostgreSQL pour Nagios
- nombreuses sondes spécifiques à PostgreSQL
- nombreuses métriques remontées
- Permet de faire la liste des points d’observation possibles
- https://github.com/OPMDG/check_pgactivity
Au programme : quelques bonnes pratiques
- La supervision
- L’audit
- La mise à jour applicative
- Le contrôle de la fragmentation
- La sauvegarde
- L’optimisation SQL
L’audit
- Objectifs :
- Approfondir la compréhension de notre instance
- Repérer les points de contentions
- Trouver les requêtes posant problème
- Quand ?
- En test et validation
- Lors de dysfonctionnements
Les outils d’audit
- Les graphiques de métrologie
- Des outils dédiés :
- pgCluu
- pgBadger
- temBoard
pgCluu
- Outils de collectes de métriques de performances
- Dépôt github
- génère un rapport HTML complet
- Différents aspects mesurés :
- informations sur le système
- consommation des ressources CPU, RAM, I/O
- utilisation de la base de données
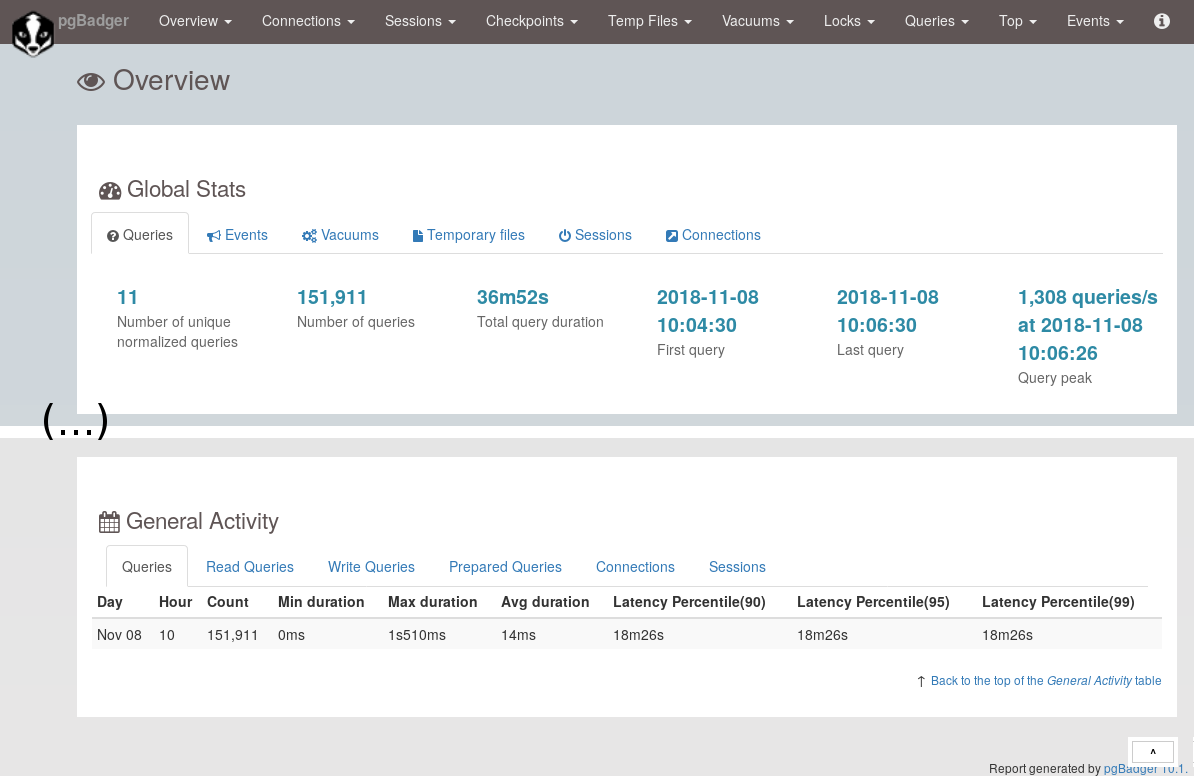
pgBadger
- Script Perl
- site officiel : https://pgbadger.darold.net/
- Traite les journaux applicatifs de PostgreSQL
- Génére un rapport HTML très détaillé
Configurer PostgreSQL pour pgBadger
- Utilisation des traces applicatives
- Où tracer ?
- Quel niveau de traces ?
- Tracer les requêtes
- Tracer certains comportements
Configuration minimale
- traces en anglais
lc_messages='C'
- ajouter le plus d’information possible
log_line_prefix = '%t [%p]: user=%u,db=%d,app=%a,client=%h '
Tracer certains comportements
log_connections,log_disconnectionslog_autovacuum_min_durationlog_checkpointslog_lock_waitslog_temp_files
Tracer les requêtes
log_min_duration_statement- en production, trace les requêtes longues
- 10000 pour les requêtes de plus de 10 secondes
- pour un audit, à 0 : trace toutes les requêtes
Création d’un rapport pgBadger
$ pgbadger postgresql-13-main.log
- Rapport dans le fichier out.html
- Très nombreuses options :
- fichier de sortie :
--outfile - filtrage par date :
--begin,--end - autres filtrages :
--dbname,--dbuser,--appname, …
- fichier de sortie :
temBoard - PostgreSQL Remote Control
- Multi-instances
- Surveillance OS / PostgreSQL
- Suivi de l’activité
- Configuration de chaque instance
- Historisation des requêtes
pg_stat_statements
Au programme : quelques bonnes pratiques
- La supervision
- L’audit
- La mise à jour applicative
- Le contrôle de la fragmentation
- La sauvegarde
- L’optimisation SQL
La mise à jour applicative
- Des nouvelles versions logicielles régulières
- Apportent :
- Des innovations
- Des améliorations
- Des corrections de dysfonctionnement
- Des corrections de failles de sécurités
Une numérotation pas simple…
- … qui se soigne
- Avant la version 10
- X.Y : version majeure (8.4, 9.6)
- X.Y.Z : version mineure (9.6.19)
- Après la version 10
- X : version majeure (10, 11, 12, 13)
- X.Y : version mineure (12.4)
- Avant la version 10
Versions majeures
- Apporte des nouvelles fonctionnalités
- Nécessite une migration des données
- Une sortie tous les 12 à 15 mois
- Maintenue environ 5 ans par la communauté
- Les versions majeures supportées : 9.6, 10, 11, 12 et 13
Mise à jour majeure
- Bien lire les Release Notes
- Bien tester l’application avec la nouvelle version
- rechercher les régressions en terme de fonctionnalités et de performances
- penser aux extensions et aux outils
- Pour mettre à jour
- mise à jour des binaires
- et mise à jour/traitement des fichiers de données
Versions non supportées
- Les versions 9.5 et inférieures : à migrer au plus vite !
- Les versions 9.6 et 10 : projet de migration à lancer
Versions mineures
- Corrections de bugs ou de failles de sécurité
- Sortie au moins trimestrielle dans toutes les versions majeures supportées
- Dernières releases (11 février 2021) :
- 13.2, 12.6, 11.11, 10.16 et 9.6.21
Mise à jour mineure
- Méthode :
- arrêter PostgreSQL
- mettre à jour les binaires
- redémarrer PostgreSQL
- Pas besoin de s’occuper des données, sauf cas exceptionnel
- bien lire les Release Notes pour s’en assurer
Au programme : quelques bonnes pratiques
- La supervision
- L’audit
- La mise à jour applicative
- Le contrôle de la fragmentation
- La sauvegarde
- L’optimisation SQL
Le contrôle de la fragmentation
- Symptôme : baisse régulière des performances
- Raison : fragmentation des tables et des index
- Cause : implémentation du
MVCC
MultiVersion Concurrency Control (MVCC)
- Le « noyau » de PostgreSQL
- Garantit ACID
- Permet les écritures concurrentes sur la même table
L’implémentation MVCC de PostgreSQL
- Colonnes supplémentaires masquées par défaut :
ctidxminetxmax
ctid
- Codée sur 6 octets
- 4 octets pour la page
- 2 octets pour la ligne
- Fournit une adresse physique dans une table
xmin et xmax (1/4)
Table initiale :
| xmin | xmax | Nom | Solde |
|---|---|---|---|
| 100 | M. Durand | 1500 | |
| 100 | Mme Martin | 2200 |
xmin et xmax (2/4)
xmin et xmax (3/4)
xmin et xmax (4/4)
| xmin | xmax | Nom | Solde |
|---|---|---|---|
| 100 | 150 | M. Durand | 1500 |
| 100 | 150 | Mme Martin | 2200 |
| 150 | M. Durand | 1300 | |
| 150 | Mme Martin | 2400 |
- Comment est effectuée la suppression d’un enregistrement ?
- Comment est effectuée l’annulation de la transaction 150 ?
Avantages du MVCC PostgreSQL
- Avantages :
- avantages classiques de MVCC (concurrence d’accès)
- implémentation simple et performante
- peu de sources de contention
- verrouillage simple d’enregistrement
- rollback instantané
- données conservées aussi longtemps que nécessaire
Inconvénients du MVCC PostgreSQL
- Inconvénients :
- Tables plus volumineuses
- Pas de visibilité dans les index
- Nettoyage des enregistrements (
VACUUM)
Fonctionnement de VACUUM (1/3)
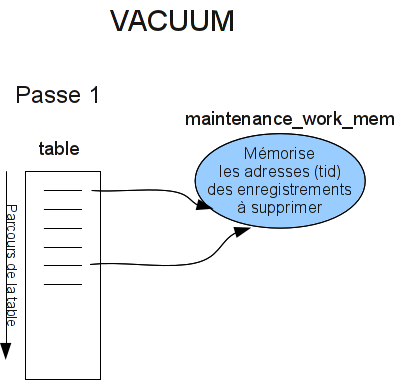
Fonctionnement de VACUUM (2/3)
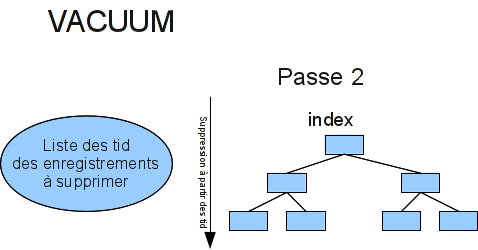
Fonctionnement de VACUUM (3/3)
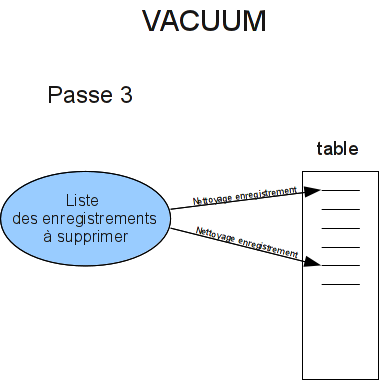
Lutter contre la fragmentation
- Supervision de la fragmentation
- Réglage de l’autovacuum
- Reconstruction régulière des index
Réglage de l’autovacuum
- Déclenchement d’un vacuum si :
nb_enregistrements_morts (n_dead_tup) >=
autovacuum_vacuum_threshold + nb_enregs × autovacuum_vacuum_scale_factor- Paramètres :
autovacuum_vacuum_threshold: 50autovacuum_vacuum_scale_factor: 20 %
Adaptation de l’autovacuum
- Déconseillé de modifier le paramétrage de façon globale
- Adaptation conseillée :
- table par table
- suivant le nombre d’enregistrements
ALTER TABLE table_name SET (autovacuum_vacuum_scale_factor = 0.05);
Reconstruction des index
- Lancer
REINDEXrégulièrement permet :- de gagner de l’espace disque
- d’améliorer les performances
- de réparer un index corrompu
VACUUMne provoque pas de réindexationVACUUM FULLréindexe- Option
CONCURRENTLYà partir de la version 12
Maintenance : script de réindexation
Au programme : quelques bonnes pratiques
- La supervision
- L’audit
- La mise à jour applicative
- Le contrôle de la fragmentation
- La sauvegarde
- L’optimisation SQL
La sauvegarde
- Opération essentielle pour la sécurisation des données
- PostgreSQL propose différentes solutions
- de sauvegarde à froid ou à chaud, mais cohérentes
- des méthodes de restauration partielle ou complète
Définir une politique de sauvegarde
- Pourquoi établir une politique ?
- Que sauvegarder ?
- À quelle fréquence sauvegarder les données ?
- Quels supports ?
- Quels outils ?
- Vérifier la restauration des sauvegardes
Objectifs
- Sécuriser les données
- Mettre à jour le moteur de données
- Dupliquer une base de données de production
- Archiver les données
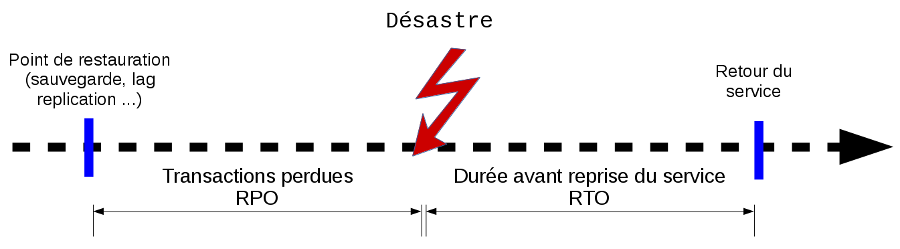
RTO / RPO
- RPO (Recovery Point Objective) : Perte de Données Maximale Admissible
- RTO (Recovery Time Objective) : Durée Maximale d’Interruption Admissible
- => Permettent de définir la politique de sauvegarde/restauration
Les sauvegardes / restaurations avec Tina
- Sauvegarde à chaud avec Time Navigator
- Permet des restaurations à n’importe quel point dans le temps
- Solution puissante… mais complexe
Mieux comprendre la sauvegarde PITR
- Point In Time Recovery
- À chaud
- En continu
- Cohérente
Write Ahead Logs, aka WAL
- Chaque donnée est écrite 2 fois sur le disque !
- Sécurité quasiment infaillible
- Comparable à la journalisation des systèmes de fichiers
Avantages des WAL
- Un seul sync sur le fichier de transactions
- Le fichier de transactions est écrit de manière séquentielle
- Les fichiers de données sont écrits de façon asynchrone
- Point In Time Recovery
- Réplication (WAL shipping)
Principes de la sauvegarde PITR
- Les journaux de transactions (WAL) contiennent toutes les modifications
- Il faut les archiver
- … et avoir une image des fichiers des données à un instant t
- La restauration se fait en restaurant cette image
- … et en rejouant les journaux dans l’ordre
Points d’attention
- Sauvegarde de l’instance complète
- Nécessite un grand espace de stockage (données + journaux)
- Risque d’accumulation des journaux en cas d’échec d’archivage
- …avec arrêt de l’instance si
pg_walplein !
- …avec arrêt de l’instance si
- Restauration de l’instance complète
Prévention des incidents liés au PITR
- Superviser l’espace disques :
- du FS de l’archivage
- du FS des données de PostgreSQL
- Savoir où se trouve la procédure de restauration…
- … et la tester régulièrement !
Au programme : quelques bonnes pratiques
- La supervision
- L’audit
- La mise à jour applicative
- Le contrôle de la fragmentation
- La sauvegarde
- L’optimisation SQL
L’optimisation SQL
- Le vrai problème de l’informatique :
- ne serait-ce pas les utilisateurs ???
- Un aperçu :
- Schéma de données mal conçu
- Pas d’indexation
- Vues imbriquées
- Requêtes baroques
- etc.
Un sujet très vaste
- La solution : la formation PERF1 de Dalibo
- Au programme :
- Configuration du système et de l’instance
- Techniques d’indexation
- Comprendre
EXPLAIN - Analyses et diagnostics
Quelques outils pour l’optimisation SQL
EXPLAIN: récupère le plan d’exécution optimalEXPLAIN ANALYSE: plan et réalisé de la requête- Difficile à lire, utiliser les outils :
Questions ? Remarques !
- Support Dalibo :
- sur la plate-forme : https://support.dalibo.com
- par mail à l’adresse : support@dalibo.com
- par téléphone au : +33 (0) 970 444 750