PostgreSQL Anonymizer
Beyond GDPR
Who I Am
Damien Clochard
PostgreSQL DBA & Co-founder at Dalibo
President of PostgreSQLFr Association
Who I Am Not
I Am Not A Lawyer
I Am Not A Privacy Expert
Don’t take my word for it / Check the links !
My Journey
Menu
Why Anonymization is hard
Anonymization Pipelines
PostgreSQL Anonymizer
Why Anonymization is hard
(source: WP29 Opinion on Anonymisation Techniques)
Singling Out
The possibility to isolate a record and identify a subject in the dataset.
Linkability
Identify a subject in the dataset using other datasets
Netflix Ratings + IMDB Ratings
Hospital visits + State voting records
(sources: Netflix prize + Hospital Reidentification )
Inference
Identify a subject using a set of indirect identifiers.
87% of the U.S. population are uniquely identified by date of birth, gender and zip code
(source : Latanya Sweeney)
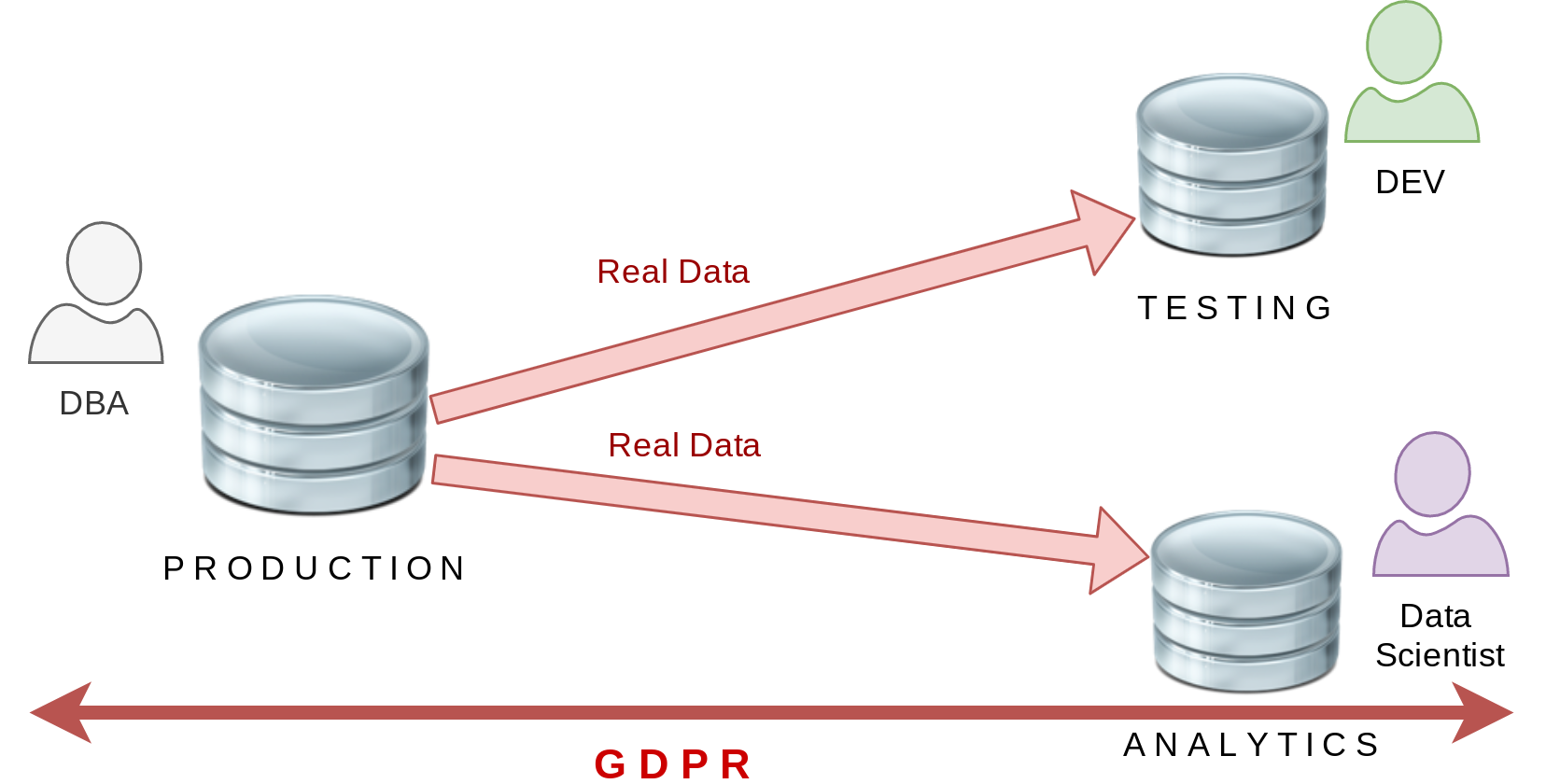
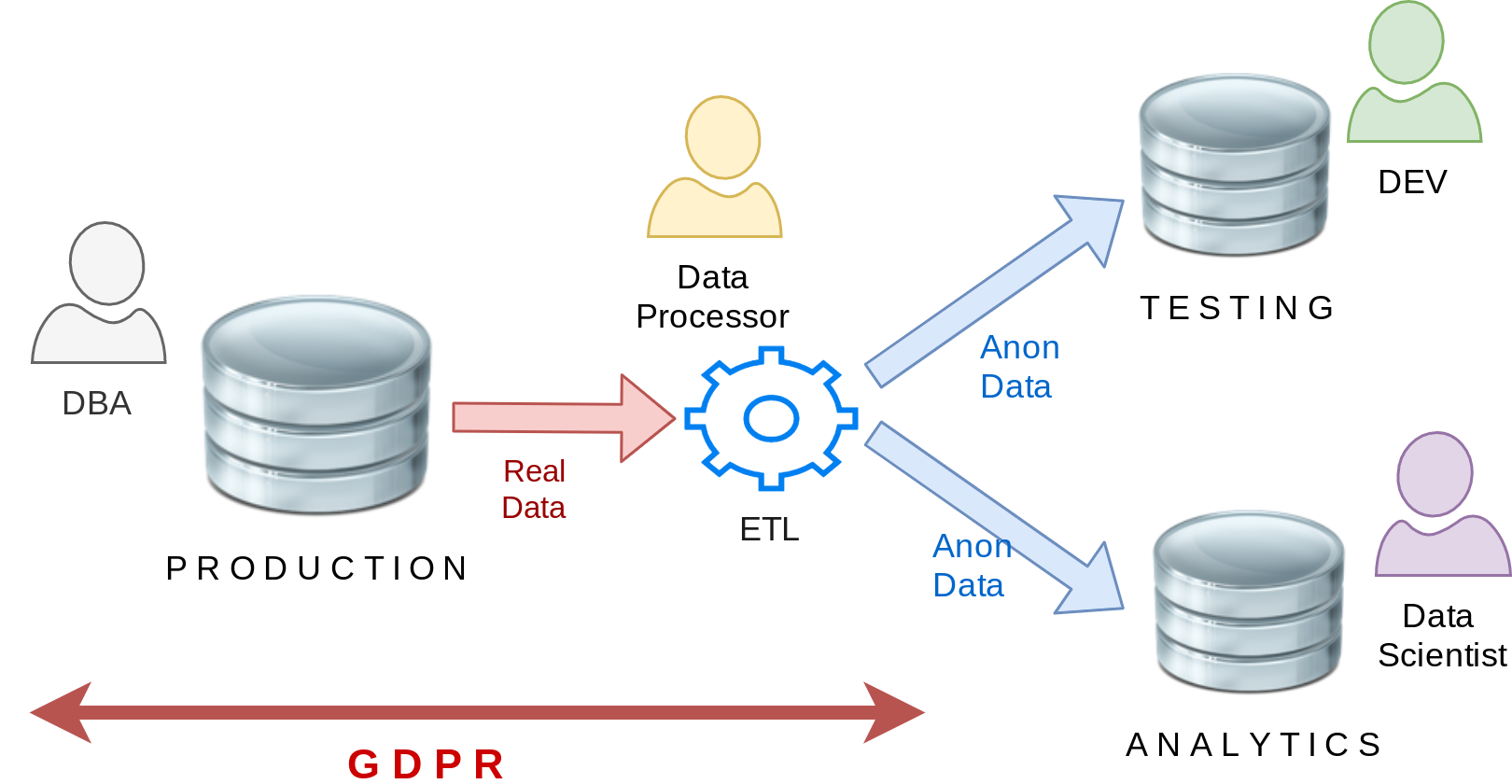
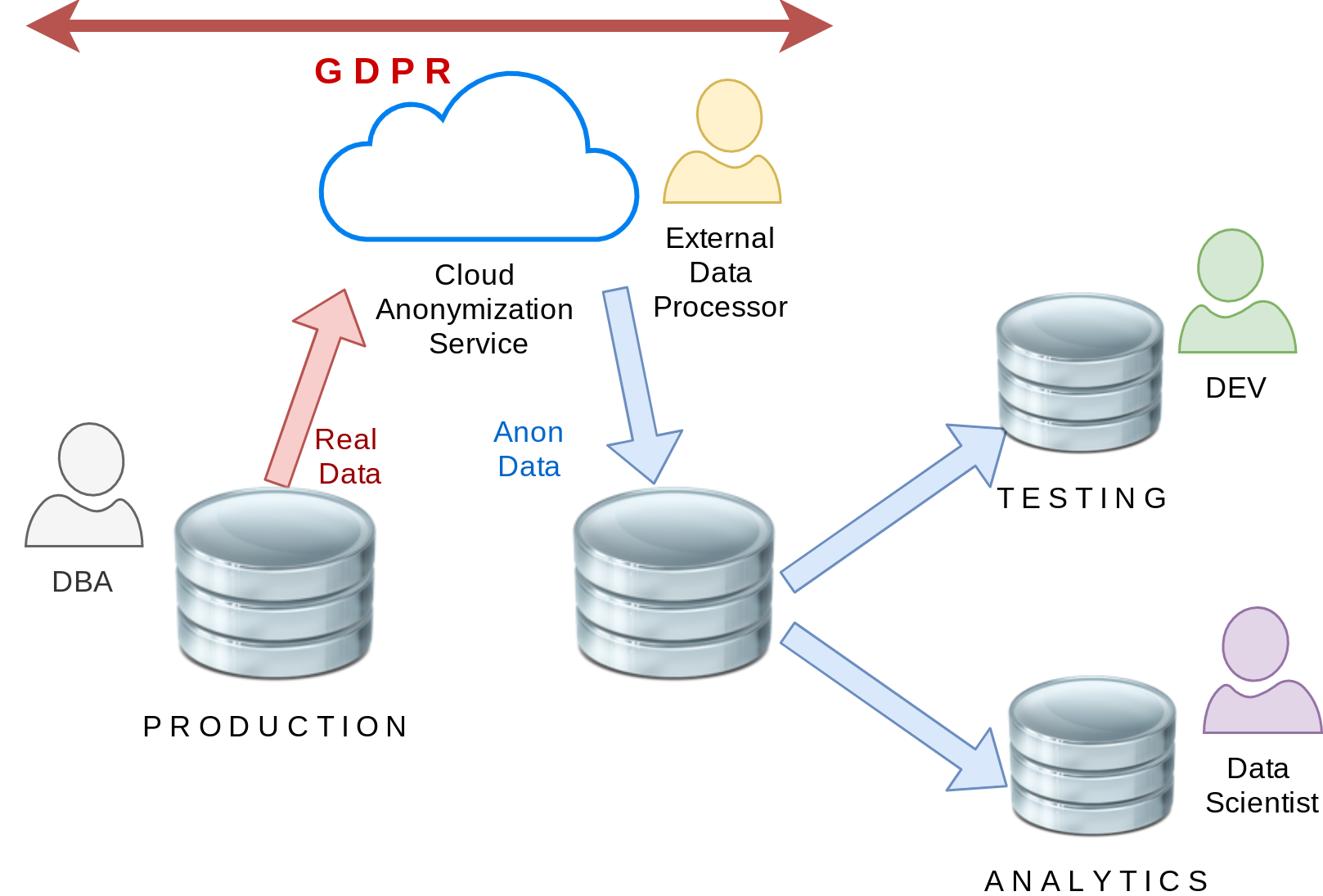
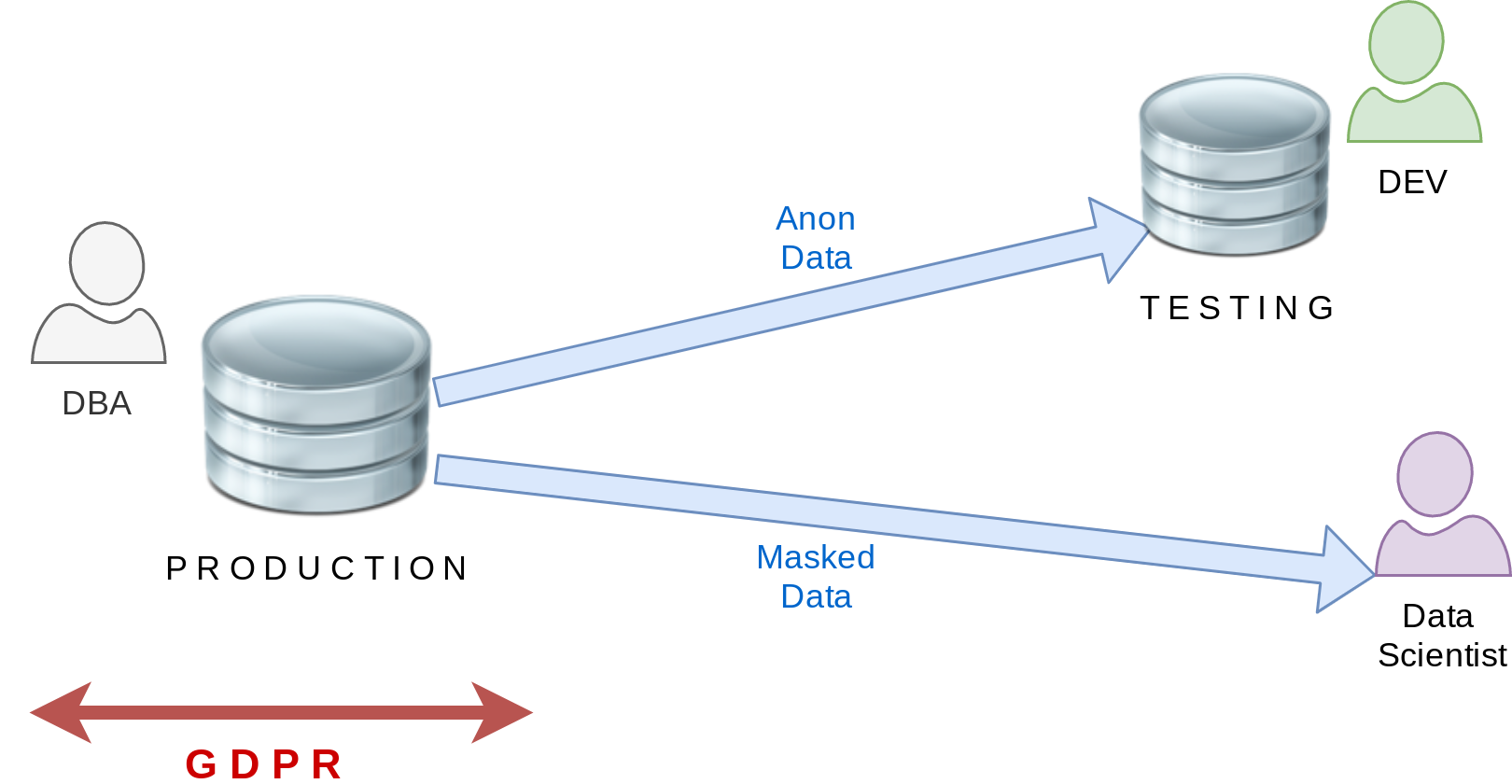
Anonymization Pipelines
Minimizing the risk of data leaks by reducing the attack surface
Basic Example

Worst Scenario
ETL
Cloud Anonymization
PostgreSQL Anonymizer

What is this ?
Started as a research project in 2018
Now part of the “Dalibo Labs” initiative
Currently in beta
Version 1.0 is coming by the end of 2020
Goals
Declare masking rules within the database model
Anonymization is done internally
Dynamic Masking / Anonymous Export / In-Place Masking
Batteries included : Builtin masking functions
Inspired by MS SQL Server Dynamic Data Masking
Example: Real Data
Example: Anonymized Data
Install
Using the Community RPM Repo:
Load & Init
Declare a masking rule
Example
CREATE TABLE player( id SERIAL, name TEXT, points INT);
INSERT INTO player VALUES
( 1, 'Kareem Abdul-Jabbar', 38387),
( 5, 'Michael Jordan', 32292 );
SECURITY LABEL FOR anon ON COLUMN player.name
IS 'MASKED WITH FUNCTION anon.fake_last_name()';
SECURITY LABEL FOR anon ON COLUMN player.id
IS 'MASKED WITH VALUE NULL';Now we have 3 options
- In-Place Anonymization
- Anonymous Dumps
- Dynamic Masking
In-Place Anonymization
In-Place Anonymization
This will update all lines of all tables containing at least one masking rule.
This is gonna be slow and trigger heavy write workloads.
Anonymous Dumps
Dynamic Masking
Let’s take a basic example :
Dynamic Masking
Step 1 : Activate the dynamic masking engine
Dynamic Masking
Step 2 : Declare a masked user
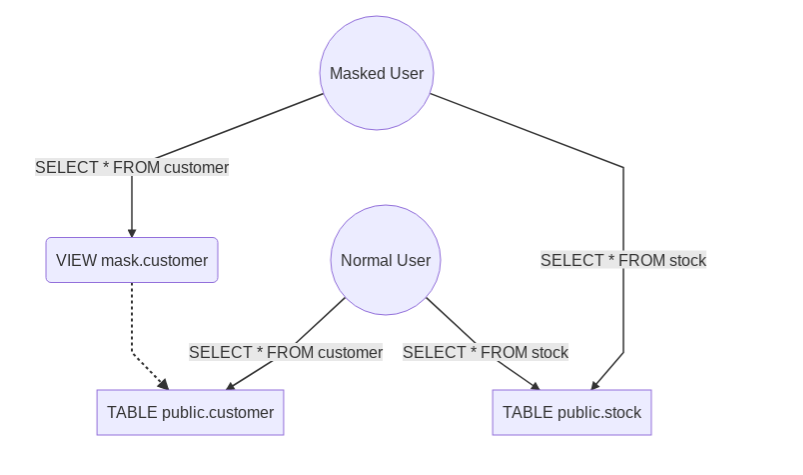
The masked user has a read-only access to the anonymized data of the masked tables.
Dynamic Masking
Step 3 : Declare the masking rules
Dynamic Masking
Step 4 : Connect with the masked user
How it Works
Batteries Included: 10 Masking techniques
- Destruction
- Noise Addition
- Shuffling / Permutation
- Randomization
- Faking / Synthetizing
- Advanced Faking
- Pseudonymization
- Hashing
- Partial Scrambling
- Generalization
Destruction
Destruction
Simple, Fast, Efficient
Required for
NOT NULLcolumns
Noise Addition
=# SECURITY LABEL FOR anon
-# ON COLUMN employee.salary
-# IS 'MASKED WITH FUNCTION
-# anon.add_noise_on_numeric_column(user, salary, 0.33)
-# ';All values of the column will be randomly shifted with a ratio of +/- 33%
Noise Addition
The dataset remains meaningful
AVG()andSUM()are similar to the originalworks only for dates and numeric values
“extreme values” may cause re-identification (“singling out”)
risk repetition attack, especially with dynamic masking
Shuffling
Shuffling
The dataset remains meaningful
Perfect for Foreign Keys
Works bad with low distribution (ex: boolean)
The table must have a primary key
Randomization
Randomization
Simple and Fast
Usefull for columns with
NOT NULLconstraintsUseless for analytics
Faking
Faking
Just a more realistic version of Randomization
Great for developpers and CI tests
You can load your own dictionnaries !
Very basic implementation
Advanced Faking
Advanced Faking
Based on the well-known Python
FakerlibraryComplete, Powerful, Extensible
Slow
Partial Scrambling
=# SECURITY LABEL FOR anon
-# ON COLUMN employee.phone
-# IS 'MASKED WITH FUNCTION anon.partial(phone,4,'******',2)';+33142928107 becomes +331******07
Partial Destruction
Similar to the “Destruction” approach
Perfect for phone number, credit cards, etc.
The user can still recognize his/her own data
Transformation is
IMMUTABLEWorks only for TEXT / VARCHAR types
Pseudonymization
Pseudonymization
This is an IMMUTABLE transformation:
Pseudonymization
Useful for Foreing Keys and UNIQUE columns
You can build an index on pseudonymized columns
Pseudonymized Data are still covered by GDPR !
Hashing
Hashing
Generalization
SELECT * FROM patient;
ssn | firstname | zip | birth | disease
-------------+-----------+---------+------------+---------------
253-51-6170 | Alice | 47012 | 1989-12-29 | Flu
091-20-0543 | Bob | 42678 | 1979-03-22 | Allergy
565-94-1926 | Caroline | 42678 | 1971-07-22 | Flu
510-56-7882 | Eleanor | 47909 | 1989-12-15 | AcneGeneralization
Generalization
SELECT * FROM generalized_patient;
firstname | zip | birth | disease
-----------+---------------+-------------------------+---------------
REDACTED | [47000,48000) | [1980-01-01,1990-01-01) | Flu
REDACTED | [42000,43000) | [1970-01-01,1980-01-01) | Allergy
REDACTED | [42000,43000) | [1970-01-01,1980-01-01) | Flu
REDACTED | [47000,48000) | [1980-01-01,1990-01-01) | AcneGeneralization
The data remains true but less precise
Ideal for data science, reporting and analytics (RANGE types)
The degree of Anonymization can be measured with the k-anonymity function
Dynamic masking won’t work (because the data model has changed)
Can’t be used in CI
Write your own Masks !
Use your own set of fake data
write simple SQL functions, easy to test and maintain
Useful for JSON columns
In a Nutshell
Write your masking rules inside the database
Different strategies for different use cases
Combine with other tools (pg_sample, pg_audit, etc.)
thanks !
Contact : damien.clochard@dalibo.com
Follow : @daamien
Other Projects : Dalibo Labs