Anonymization et Masquage Dynamique avec PostgreSQL
Bonjour
Damien Clochard
PostgreSQL DBA & Co-foundateur de Dalibo
Président de l’association PostgreSQLFr
Je ne suis pas juriste !
Mon chemin
Menu
RGPD : 1 an plus tard…
Pourquoi c’est difficile ?
Flux d’anonymisation
PostgreSQL Anonymizer
7 Techniques d’anonymisation
RGPD
Droits Individuels
Principes
Impact
Pseudonymisation vs. Anonymisation
RGPD : les droits Individuels
- droit à l’information (Art. 13 et Art. 14)
- droit d’accès (Art. 15)
- droit de rectification (Art. 16)
- droit à la portabilité (Art 20)
- droit d’opposition (Art. 21)
- droit à l’oubli (Art. 17)
- droit à la limitation du traitement (Art. 18)
- droit de décision automatisée (Art. 22)
(sources: Individual Rights)
RGPD: Principes & Concepts
- Licéité, loyauté, transparence
- Sécurité
- Minimisation des données
- Privacy By Design
- Data Protection By Design
- Pseudonymisation
- Limitation du stockage
- Précision
- Limitation des finalités
(source: GDPR Principles)
Sanctions are coming
- Juillet 2019 : 110M€ pour Marriott (UK)
- Juillet 2019 : 204M€ pour British Airways (UK)
- Juin 2019 : 400k€ pour Sergic (France)
- Juin 2019 : 250 k€ pour LaLiga (Espagne)
- Mai 2019 : 170 k€ pour la ville de Bergen (Norvège)
- Avril 2019 : 200k€ pour Airbus (France)
- etc.
(source: GDPR Enforcement Tracker)
Attention à l’article 32 !
La plupart des scanctions concernent l’article 32 :
« Mesures techniques et organisationnelles insuffisantes pour assurer la sécurité de l’information »
Autrement dit : “Fuites de données”
(source Article 32 - Sécurité du traitement)
Pseudonymisation
« traitement de données à caractère personnel de telle façon que celles-ci ne puissent plus être attribuées à une personne concernée précise sans avoir recours à des informations supplémentaires »
Pseudonymisation != Anonymisation
Pseudonymisation est méthode de protection de données.
Exemples : Chiffrement ou Hashage
Les données peuvent reconstruites avec des données supplémentaires
Les données pseudonymisées restent soumises au RGPD
L’anonymisation est la seule véritable porte de sortie
Pourquoi c’est difficile ?
(source: WP29 Opinion on Anonymisation Techniques)
Singularisation / Singling out
Identifier un sujet à partir de valeurs rares ou extrèmes
Recoupements / Linkability
Identifier un sujet en utilisant des jeux de données externes
Notes Netflix + Notes IMDB
Registre d’un hopital + Liste électorale
(sources: Netflix prize + Hospital Reidentification )
Inférence
Identifier un sujet en regroupant plusieurs identifiants indirects
87% de la population des Etats-Unis est identifiable à partir de la date de naissance, du genre et du code postal.
(source : Latanya Sweeney)
C’est perdu d’avance !
On ne peut pas prouver que la ré-identification est impossible
(source: De-indentification still doesn’t work)
Le RGPD reconnait le problème
« Pour déterminer si une personne physique est identifiable, il convient de prendre en considération l’ensemble des moyens raisonnablement susceptibles d’être utilisés par le responsable du traitement ou par toute autre personne pour identifier la personne physique directement ou indirectement »
(source: Recital 26)
Mesurer la prise de risque
Il faut mesurer le “risque raisonable” de ré-identification de manière régulière.
Flux d’anonymisation
Objectif : minimiser le risque de fuites de donnée réduisant la surface d’attaque
C’est aussi une application directe du principe Limitation du stockage
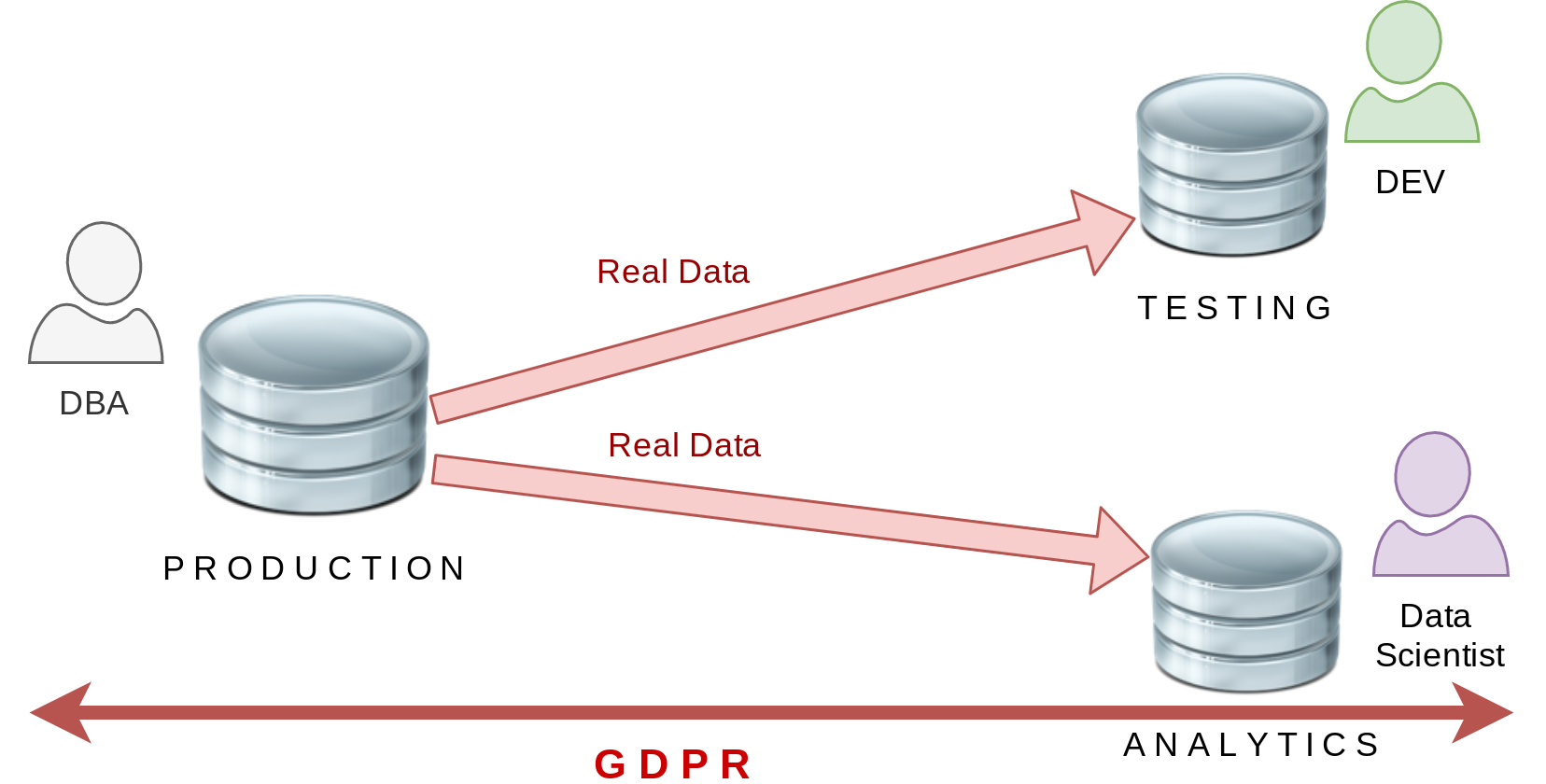
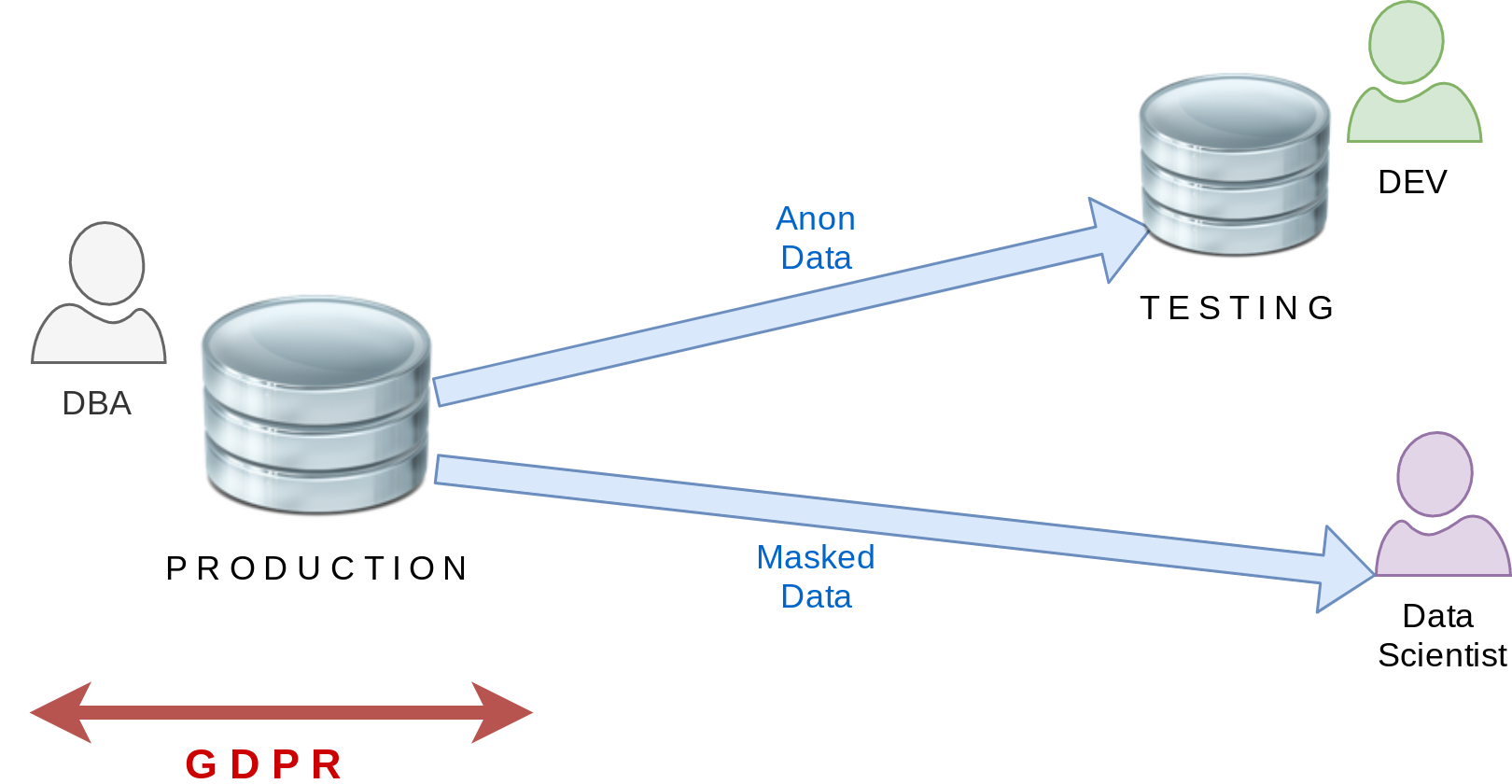
Exemple de base

Pas d’anonymization
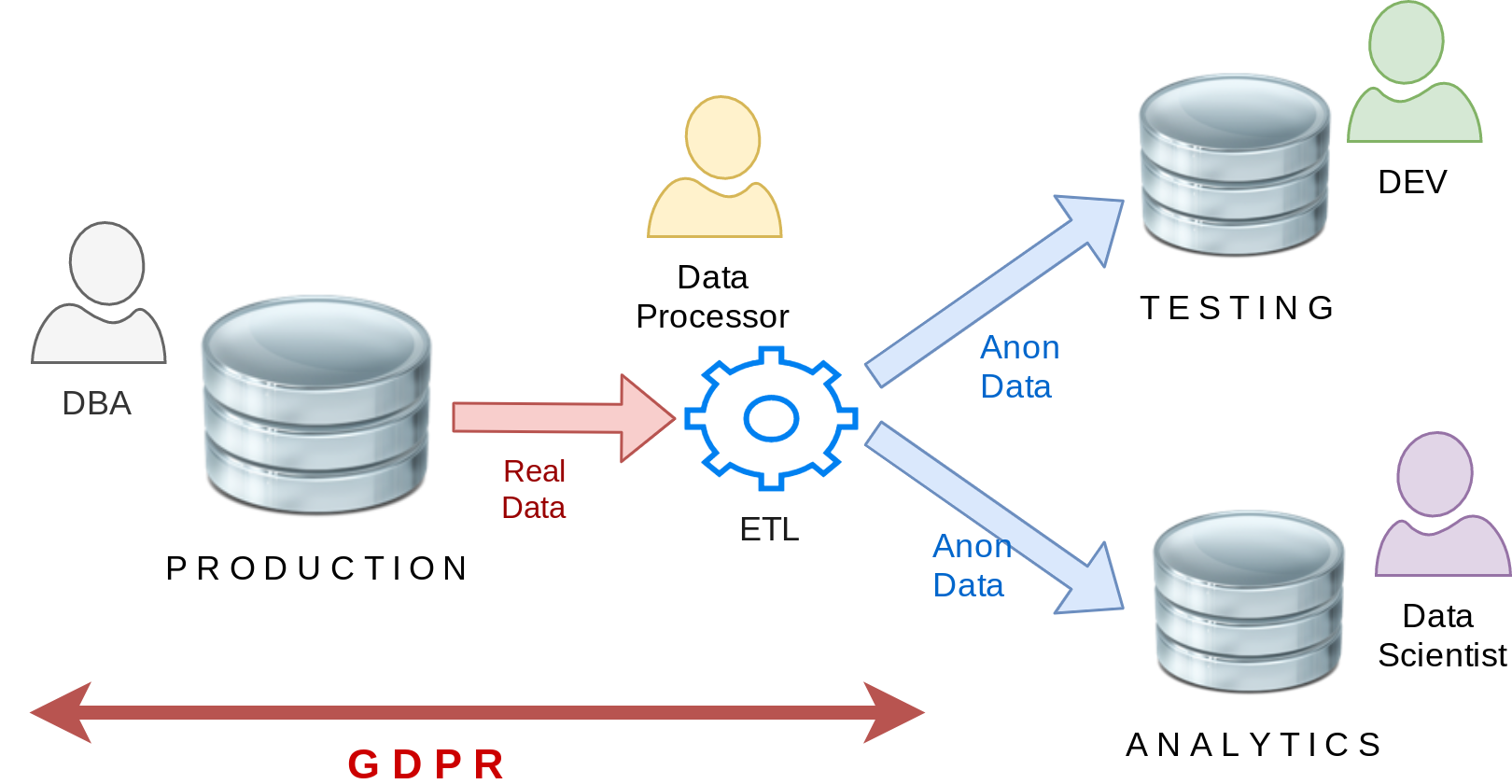
ETL
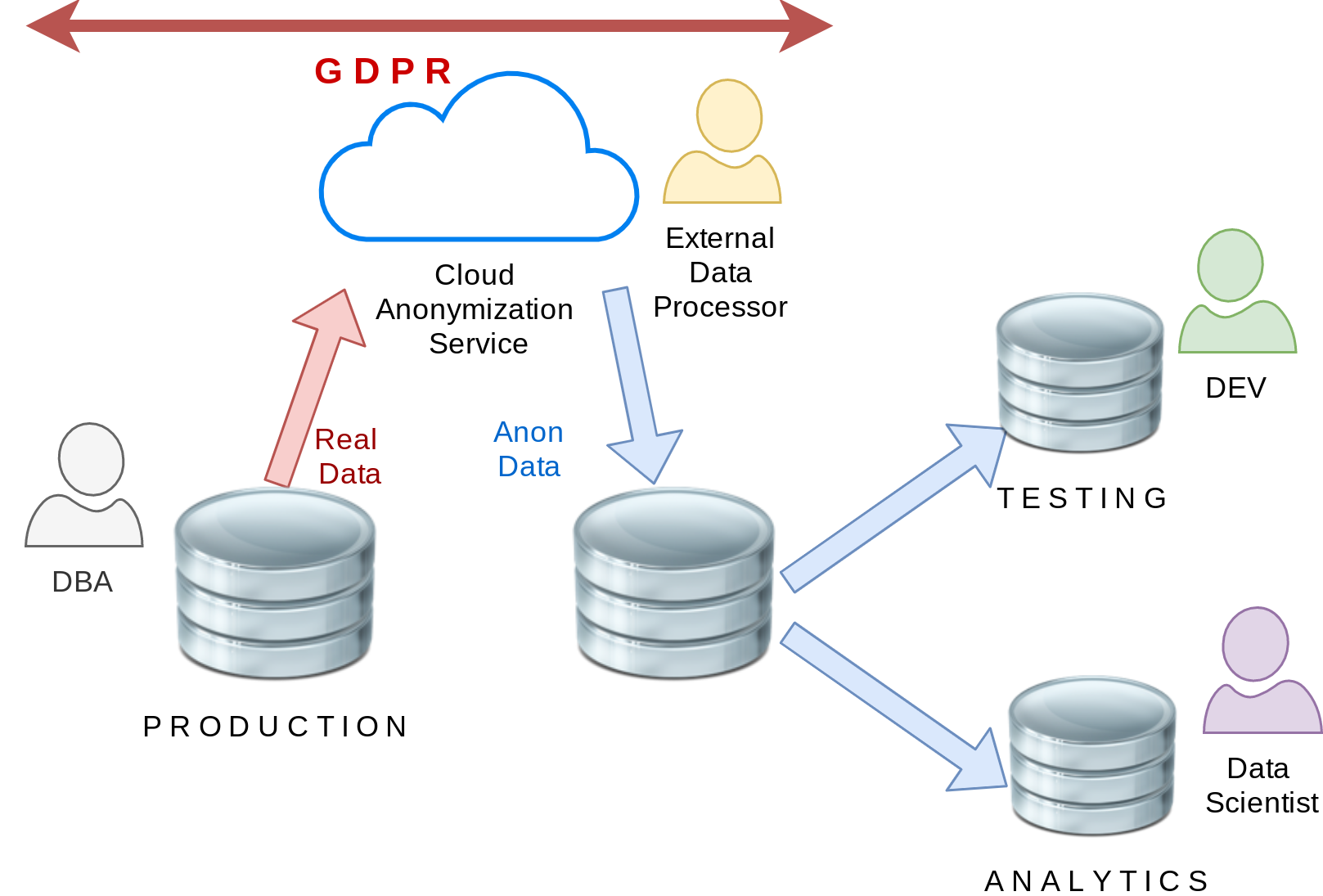
Anonymisation dans les nuages (!?!)
PostgreSQL Anonymizer

Objectifs
Déclarer des règles de masquage à l’intérieur de la base de données
Anonymiser à l’intérieur de PostgresQL
Masquage Dynamique ou Substition Permanente
Un panel de fonctions de masquage
Reprendre la syntaxe du Masquage Dynamique de SQL Server
Example : Données Réelles
Exemple : Données Anonymisées
Installer
A partir du dépot RPM de la communauté :
Configurer
Charger
Declarer une règle de masquage
Ensuite 3 approches sont possibles
Substitution Permanente (“In-Place Anonymization”)
Export Anonyme (“Anonymous Dump”)
Masquage Dynamique (“Dynamic Masking”)
Substitution Permanente
Substitution Permanente
Réécriture (UPDATE) de toutes les lignes de toutes les tables masquées.
Export Anonyme
Export Anonyme
Masquage Dynamique
Exemple de base :
Masquage Dynamique
Etape 1 : Activer le moteur de masquage
Masquage Dynamique
Etape 2 : Déclarer utilisateur masqué
L’utilisateur masqué a un accès en lecture seule aux données anonymisées.
Masquage Dynamique
Etape 3 : Declarer les règles de masquage
Masquage Dynamique
Etape 4 : Se connecter avec l’utilisateur masqué
Techniques d’Anonymisation
L’extension fournit toute une batterie de fonctions pour appliquer 7 techniques d’anonymization:
- Destruction
- Bruit
- Brassage
- Randomization
- Imitation (faking)
- Destruction partielle
- Généralisation
Destruction
Destruction
- Simple
- Rapide
- Efficace
Bruit
Toutes les valeurs seront décalées aléatoirement avec un ratio de +/- 10%
Bruit
Les données restent réalistes.
AVG()etSUM()sont similaires à l’originalmarche uniquement avec les dates et les valeurs numériques
Les “valeurs marginales” sont un risque de ré-identification (“singularisation”)
Attention aux attaques par répétition ! Ne pas utiliser avec le masquage dynamique
Brassage
Brassage
Les données ne sont pas modifiées
Parfait pour les clés étrangères
Marche mal avec les distributions peu ou mal distribuées (ex: booléens)
La table doit avoir une clé primaire
Randomisation
Randomisation
Simple et rapide
Utile pour les colonnes avec la contrainte
NOT NULLA éviter pour les stats et l’analytique
Imitation ( Faking )
Imitation ( Faking )
Une version plus élaborée de la randomisation
Parfait pour les dev, les démos, les tests CI, etc.
Vous pouvez charger vos propres données factices !
Destruction Partielle
=# SECURITY LABEL FOR anon
-# ON COLUMN employee.phone
-# IS 'MASKED WITH FUNCTION anon.partial(phone,4,'******',2)';+33142928107 devient +331******07
Destruction Partielle
Parfait pour les numéros de téléphone, cartes de crédit, etc.
Le sujet peut toujours reconnaitre sa donnée
La transformation est
IMMUTABLEMarche seulement pour les types TEXT / VARCHAR
Generalization
SELECT * FROM patient;
ssn | firstname | zip | birth | disease
-------------+-----------+---------+------------+---------------
253-51-6170 | Alice | 47012 | 1989-12-29 | Flu
091-20-0543 | Bob | 42678 | 1979-03-22 | Allergy
565-94-1926 | Caroline | 42678 | 1971-07-22 | Flu
510-56-7882 | Eleanor | 47909 | 1989-12-15 | AcneGeneralization
Generalization
SELECT * FROM generalized_patient;
firstname | zip | birth | disease
-----------+---------------+-------------------------+---------------
REDACTED | [47000,48000) | [1980-01-01,1990-01-01) | Flu
REDACTED | [42000,43000) | [1970-01-01,1980-01-01) | Allergy
REDACTED | [42000,43000) | [1970-01-01,1980-01-01) | Flu
REDACTED | [47000,48000) | [1980-01-01,1990-01-01) | AcneGeneralization
Les données restent vraies mais moins précises
Utilise les types RANGE
Idéal pour les statistiques et l’analyse de données
Le dégré d’anonymisation est quantifiable avec l’indicateur de k-anonymat
Le masque dynamique ne marche pas car le schéma est différent
Inutilisable pour les tests d’intégration
En résumé
Les sanctions du RGPD sont bien réelles
Les fuites de données sont le plus gros risque
Reduire la surface d’attaque
Anonymiser dès que possible
Anonymiser dans la base de données
Différentes techniques pour différents usages
Le chiffrement n’est pas de l’anonymisation !
Bataille pour la vie privée
Les développeurs doivent écrire les règles de masquage
C’est difficile…. PostgreSQL est un bon point de départ
La bataille de l’open source est gagnée,
… il faut maintenant se battre pour protéger la vie privée
Comment Contribuer ?
Feedback et bugs !
Images et geodata
rejoindre le projet sur :
Dalibo recrute
- DBA de Production
- DBA d’études
- Développeur⋅se backend Python
- Commercial Grands Comptes
Merci !
Contact : damien.clochard@dalibo.com
Follow : @daamien
Nos autres Projets : Dalibo Labs