Et PAF, ça bascule!
Stefan Fercot
26 juin 2018
Qui suis-je?
- Stefan Fercot
- aka. pgstef
- utilise PostgreSQL depuis 2010
- dans la communauté depuis 2016
- @dalibo depuis 2017
Dalibo
- Services
 Support |
 Formation |
 Conseil |
- Participation active à la communauté
- Dalibo recrute des DBA !!!
Introduction
PostgreSQL et la réplication en flux
- système robuste et performant
- sécurité des données
- pas de service hautement disponible
Bascule automatique - complexité
- comment détecter une vraie défaillance ?
- le maître ne répond plus ?
- est-il vraiment éteint ?
- est-il vraiment inactif ?
- comment réagir à une panne réseau ?
- comment éviter les split brain ?
Pacemaker
- est LA référence de la HA sous Linux
- est un “Cluster Resource Manager”
- supporte les fencing, quorum et watchdog
- s’interface avec n’importe quel service
- multi-service, avec dépendances, ordre, contraintes, règles, etc
- chaque service a son Resource Agent
Et PAF dans tout ça?
- garder Pacemaker: il fait tout et bien à notre place
- se concentrer sur notre métier: PostgreSQL
- PAF est un Resource Agent utilisé par Pacemaker
Installation
Prérequis
- 2 nœuds ou plus
- PostgreSQL installé
- réplication fonctionnelle
- template recovery.conf.pcmk
standby_mode = onprimary_conninfo = 'host=ha-vip application_name=hostname'recovery_target_timeline = 'latest'
Installer Pacemaker et PAF
yum install -y pacemaker resource-agents pcs
yum install -y fence-agents-all fence-agents-virsh
yum install -y resource-agents-paf
systemctl disable corosync
systemctl disable pacemakerLe paquet resource-agents-paf est disponible directement dans le dépôt PGDG.
Authentifier chaque nœud à l’aide de l’outil d’administration pcs
systemctl enable pcsd
systemctl start pcsd
passwd hacluster
pcs cluster auth hanode1 hanode2 hanode3 -u haclusterCréer le cluster
pcs cluster setup --name cluster_pgsql hanode1 hanode2 hanode3
pcs cluster start --all
pcs resource defaults migration-threshold=3
pcs resource defaults resource-stickiness=10État du cluster - 1
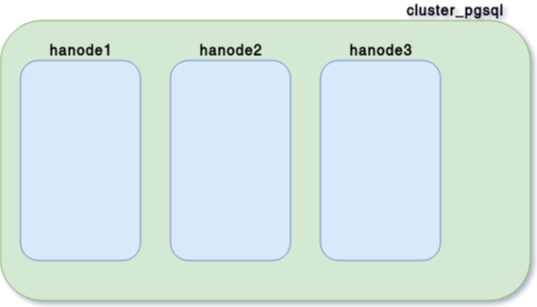
Fencing
- chaque brique doit toujours être dans un état déterminé
- garantie de pouvoir sortir du système un élément défaillant
- implémenté dans Pacemaker au travers du daemon
stonithd
Configuration du fencing
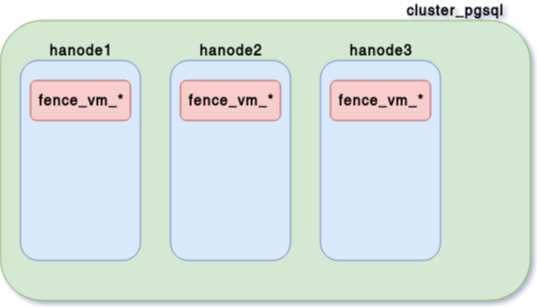
- Une ressource de fencing pour chaque nœud
pcs stonith create fence_vm_hanode1 fence_virsh \
pcmk_host_check="static-list" pcmk_host_list="hanode1" \
ipaddr="192.168.122.1" login="root" port="hanode1" \
action="reboot" identity_file="/root/.ssh/id_rsa"- Une contrainte d’exclusion pour chacune de ces ressources
pcs constraint location fence_vm_hanode1 avoids hanode1=INFINITYÉtat du cluster - 2
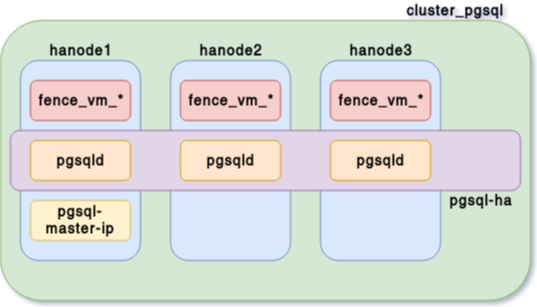
Création des ressources PostgreSQL - 1
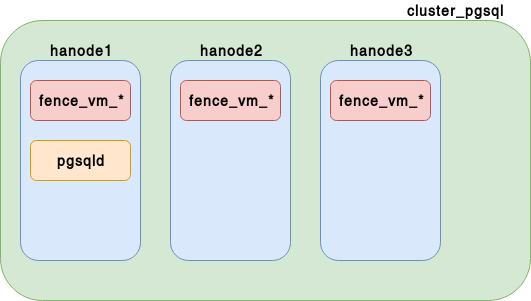
pgsqld- propriétés de l’instance PostgreSQL
pcs resource create pgsqld ocf:heartbeat:pgsqlms \
bindir=/usr/pgsql-10/bin pgdata=/var/lib/pgsql/10/data \
recovery_template=/var/lib/pgsql/recovery.conf.pcmk \
op start timeout=60s \
op stop timeout=60s \
op promote timeout=30s \
op demote timeout=120s \
op monitor interval=15s timeout=10s role="Master" \
op monitor interval=16s timeout=10s role="Slave" \
op notify timeout=60sÉtat du cluster - 3
Création des ressources PostgreSQL - 2
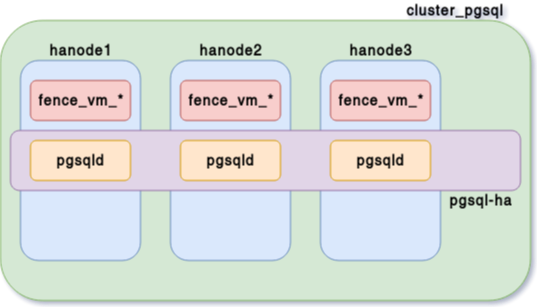
pgsql-ha- clone la ressource
pgsqldsur l’ensemble des nœuds du cluster - décide où est promue l’instance primaire,…
- clone la ressource
pcs resource master pgsql-ha pgsqld notify=trueÉtat du cluster - 4
Création des ressources PostgreSQL - 3
pgsql-master-ip- contrôle l’IP virtuelle ha-vip (192.168.122.110)
- doit être démarrée sur le nœud hébergeant la ressource maître
pcs resource create pgsql-master-ip ocf:heartbeat:IPaddr2 \
ip=192.168.122.110 cidr_netmask=24 \
op monitor interval=10s
pcs constraint colocation add pgsql-master-ip \
with master pgsql-ha INFINITYAjout de contraintes d’ordre
- l’IP virtuelle doit rester fonctionnelle sur le maître pendant le demote
- l’IP virtuelle ne doit être démarrée sur le nouveau maître qu’après promote
L’ordre de start/stop et promote/demote doit donc être asymétrique.
pcs constraint order promote pgsql-ha \
then start pgsql-master-ip symmetrical=false kind=Mandatory
pcs constraint order demote pgsql-ha \
then stop pgsql-master-ip symmetrical=false kind=MandatoryÉtat du cluster - 5
Validation - 1
pcs status
Cluster name: cluster_pgsql
Stack: corosync
Current DC: hanode2 (version 1.1.16-12.el7_4.8-94ff4df)
- partition with quorum
Last updated: ...
Last change: ... by root via crm_attribute on hanode1
3 nodes configured
7 resources configured
Online: [ hanode1 hanode2 hanode3 ]
...Validation - 2
...
Full list of resources:
fence_vm_hanode1 (stonith:fence_virsh): Started hanode2
fence_vm_hanode2 (stonith:fence_virsh): Started hanode1
fence_vm_hanode3 (stonith:fence_virsh): Started hanode1
Master/Slave Set: pgsql-ha [pgsqld]
Masters: [ hanode1 ]
Slaves: [ hanode2 hanode3 ]
pgsql-master-ip (ocf::heartbeat:IPaddr2): Started hanode1Vérification
$ psql -h ha-vip
postgres=# SELECT application_name, client_addr, state, sync_state
FROM pg_stat_replication;
application_name | client_addr | state | sync_state
------------------+-----------------+-----------+------------
hanode3 | 192.168.122.113 | streaming | async
hanode2 | 192.168.122.112 | streaming | async
(2 rows)
postgres=# SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Gestion du cluster
Afficher les ressources
pcs resource show
Master/Slave Set: pgsql-ha [pgsqld]
Masters: [ hanode1 ]
Slaves: [ hanode2 hanode3 ]
pgsql-master-ip (ocf::heartbeat:IPaddr2): Started hanode1Stop
pcs resource disable pgsql-ha
pcs cluster stop --allStart
pcs cluster start --all
pcs resource enable pgsql-haExclure un nœud du cluster
- Exclure
pcs resource ban --wait pgsql-ha hanode2- Réintégrer
pcs resource clear pgsql-ha hanode2Forcer le déplacement d’une ressource
- Déplacer
pcs resource move --wait --master pgsql-ha hanode1- Nettoyer les scores
pcs resource clear pgsql-haDémo
Failover 1 - démo
- kill -9 des processus postgres
Failover 1 - explications
kill -9 des processus postgres
- Le monitor de la ressource passe en “failed”
- Pacemaker redémarre la ressource sur le noeud
Failover 2 - démo
- Suppression du fichier
/var/lib/pgsql/10/data/global/pg_control
Failover 2 - explications
Suppression du fichier
/var/lib/pgsql/10/data/global/pg_control- L’agent PAF détecte une erreur
- Monitor en failed
- Tentative de redémarrage en échec
- Fencing de hanode1
- Choix de l’instance avec le LSN le plus élevé
- Promotion
- Déplacement de la VIP
Failover 3 - démo
echo c > /proc/sysrq-trigger
Failover 3 - explications
echo c > /proc/sysrq-trigger- Détection de l’indisponibilité de hanode1
- Fencing de hanode1
- Choix de l’instance avec le LSN le plus élevé
- Promotion
- Déplacement de la VIP
Switchover - démo
Switchover - explications
- hanode2 : demote de
pgsql-haet arrêt depgsql-master-ip - hanode1 : promotion de PostgreSQL
- Promotion de hanode1
- Démarrage de la vip sur hanode1
Conclusion
- RPO (“recovery point objective”): Streaming Replication
- RTO (“recovery time objective”) : bascule automatique
La bascule automatique apporte de la complexité.
En avez-vous vraiment besoin?
Où
- site officiel: http://clusterlabs.github.io/PAF/
- code: https://github.com/ClusterLabs/PAF
- rpm ou deb: dans les dépôts PGDG !
- documentation: https://clusterlabs.github.io/PAF/documentation.html
- support: https://github.com/ClusterLabs/PAF/issues
- mailing list : users@clusterlabs.org
Des questions ?
